Categories
Reading time
At Full Fact, we build AI Tools to help fact checkers monitor the enormous amounts of media they encounter every day. As well as online newspapers and social media posts, our users want to monitor news broadcasts, YouTube videos, radio programmes, podcasts and live events like speeches and debates. Here we discuss how we recently upgraded our transcription tools to use generative AI models.
Our tools look for claims related to topics our users want to monitor, then determine if those claims are likely to be of interest to a fact checker. Finally, we match the claims with any previous checks to track the spread of debunked misinformation and disinformation. We have written before about how we leverage AI to do this.
Fact checkers must prioritise accuracy. Therefore it is essential that transcripts are high-quality. This is a difficult task because fact checkers are not only interested in monitoring good recordings of people speaking in isolation. Speeches at rallies with noisy crowds; low-quality, phone-filmed pieces to camera; debates where several people shout at once; or simply strong accents can push a transcription model to its limits. Fact checkers may also monitor poor-quality livestreams in places where internet speeds are slow. These transcripts are, of course, no less likely to contain harmful mis- and disinformation than a cosy studio chat.
We have been using Google’s Chirp Speech-to-Text v2 model for several years, but have noticed that it can struggle with some of those trickier scenarios. Having had successes in deploying generative AI models in other parts of our pipeline, we were interested in experimenting with generative AI for transcription. The right model might also bring down our transcription costs.
Given their deployment in other Full Fact AI tools, we stuck with Google’s Gemini models for this experiment. Alongside Chirp V2, we looked at four models (increasing in price, ranging from $0.30 to $10 per million tokens):
Data
A high-quality and diverse set of audio clips was needed to properly analyse these models. Full Fact’s AI tools currently work in English, French and Arabic (with 20+ more languages planned) so varied audio types in these languages with a range of accents needed to be covered. A model that performs strongly across the three will likely also be strong in other major languages, but this will need to be verified.
YouTube videos in the dataset included a podcast, televised debates, political speeches, live comedy, reality TV, news programmes, a phone-recorded school debate, and amateur content. We found these by manually searching YouTube, with search terms relating to regions, events and types of speech in mind. Speakers from across the Anglosphere, Francosphere and the Arab-speaking world were used. Arabic is especially important to cover broadly, as there are many distinct dialects.
We noticed that some videos transitioned between languages, such as a Kenyan news broadcast in English and Swahili. We should study multiple-language performance in future.
Experiments
We extracted the audio from 23 videos and each audio file was transcribed using four Gemini models and Chirp v2. Some generative AI models may write better transcripts with extra visual context, but this was not investigated.
The Gemini models were passed the audio file along with the prompt in Fig. 1A using the Vertex API. Chirp transcripts did not contain any diarisation - indications of who is speaking when.

Fig. 1: A (top): the prompt used for generative AI transcripts. B (bottom): part of a transcript of a clip of a British election debate in 2015, created by 2.5-flash.
The transcripts were stripped of timestamps, speakers and punctuation.
As in Fig. 2, the unpunctuated words for two transcripts at a time were put into files. For each transcript, 10 of these files were made: one for each possible pair of the five models (these 10 pairs are seen in Fig. 3). Across 23 videos, this created 230 comparison files.
Comparisons were made in pairs for simplicity so we could aggregate results across all models later.
Comparisons for English and French transcripts were made by eye, by looking at a comparison file while the video played. A ‘winner’ was decided, and scored from 1-5 with a higher number indicating a more superior transcript.

Fig. 2: an example comparison file for a section of a clip of an Indian school debate. Red words only appear in the 2.5-flash (25F) transcript; green words only in the Chirp transcript; and white in both. Yellow highlights show where a word was partly different.
Rather than check all 230 files, a random sample of English and French comparisons was taken, with extras added to get good coverage across pairs of models, or to study videos of particular interest in more detail. This allowed us to estimate which model in every pair was better, and by how much.
Two models (gemini-2.0-flash and gemini-2.5-flash) initially appeared similar in quality, so we analysed all videos for this pair.
Results
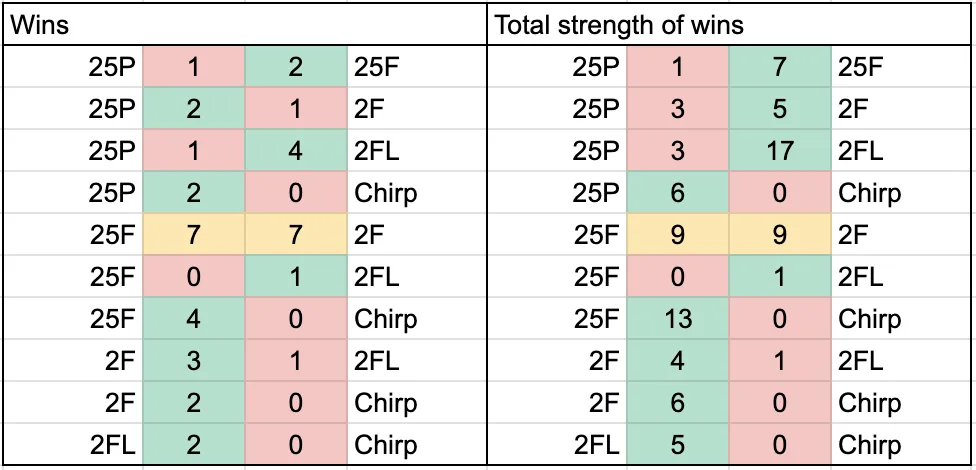
Fig. 3: table showing aggregated head-to-head results. (25P: gemini-2.5-pro, 25F: gemini-2.5-flash, 2F: gemini-2.0-flash, 2FL: gemini-2.0-flash-lite.) The ‘Wins’ columns show the number of times each model won or lost against the other in that row. The ‘Total strengths’ column adds up the scores for each win.
The first major finding was that Chirp was always outperformed by Gemini models for any transcript analysed.
2.5-pro (25P) often performed very strongly, particularly on difficult accents, but was temperamental and often cut the transcript short very early. We could not present an unreliable product to fact checkers, and having to frequently rerun transcriptions would increase costs. However, it is worth noting that a preview version of the model was used and that this may be resolved in future.
The 2.0-flash-lite (2FL) model suffered from similar problems, but generally had a lower quality of transcript anyway.
As frontrunners, every comparison file for the 2.5-flash (25F) and 2.0-flash (2F) models was analysed, resulting in a tie. The differences were marginal in every comparison. Therefore, on the basis of cost it was decided to use gemini-2.0-flash for transcription in English and French.
We asked colleagues at the Arabic Fact Checking Network to complete the same task for Arabic videos. Their evaluation of the best model aligned with Full Fact’s.
Conclusion
Developments in generative AI are frequent, so the current model will likely be superseded soon, if not already. Full Fact has existing technical infrastructure to support Google’s models, but if one of the vast number of other generative models performs better in future studies, it could be used instead. The models studied were all-purpose base Gemini models, so it is possible a specialised transcription model could perform even better. We could also study the quality of diarisation to better annotate the transcripts with the speakers’ names.
A human will always check the source of a claim from a transcript found by our tools but with improved transcripts, a fact checker will be able to monitor even more broadcasts, podcasts and videos with high levels of trust, freeing up valuable time to check more harmful claims.